
How AI gets AMNOG wrong – and what to do about it
Ask a general-purpose AI about the zVT (comparator) the G-BA assigned for a specific indication five years ago, and you will get a detailed self-confident answer. Whether it is accurate is a separate question: the model may have ingested G-BA decisions during training, pulled fragments from a web search, or filled gaps with plausible-sounding hallucinations. You cannot tell which. In market access, that ambiguity alone makes the answer professionally unusable.
This is not an argument against AI, quite the opposite. Teams are already using ChatGPT, Claude, Gemini and Copilot, mostly through individual experimentation. That is a reasonable starting point; but how do you get answers you can actually rely on for decisions that affect reimbursement outcomes?
Claude’s skills are a great next step. A skill is a packaged set of re-usable prompts and code. What makes skills go beyond prompt libraries is the code. This is how you can combine the flexibility of language models with the reliability of explicitly programmed logic. But let’s first take a look at how things go wrong.
What Claude gets wrong about AMNOG data
Take a simple AMNOG-related question like “Which zVT did the G-BA choose for Diflunisal?”.
Without a skill, Claude searches the G-BA and IQWiG websites, finds nothing useful, tries DuckDuckGo and Yahoo, ends up on web.archive.org, and, after burning tokens for 15 minutes, eventually admits defeat: It stops researching … and returns a factually wrong answer:
With access to our AMNOG skill, Claude returns the correct answer in seconds; a link to a verifiable source included:

That query was an easy case, and Claude still got it wrong. For a simple query like this, we may even spot the errors. But what happens if we want to use Claude’s visualization capabilities and ask for something more interesting?
Consider this task: “Create a bar chart showing AMNOG assessments by year from 2020 to 2026, grouped by extent of added value. Show the names of the drugs in every group. Provide links to the drugs.”
Without the skill, Claude again searches the entire internet for relevant data, finds partial sources, and finally produces a beautiful chart with a very authoritative air. What we can’t see: The data is wrong. There were close to 200 AMNOG assessments in 2021; Claude’s chart shows fewer than 60. Additionally, the links are dead ends which only fake trustworthiness. Clicking any of them takes you to the G-BA’s start page, with no information on a specific assessment. So, where did Claude find the data behind this chart? We don’t know.
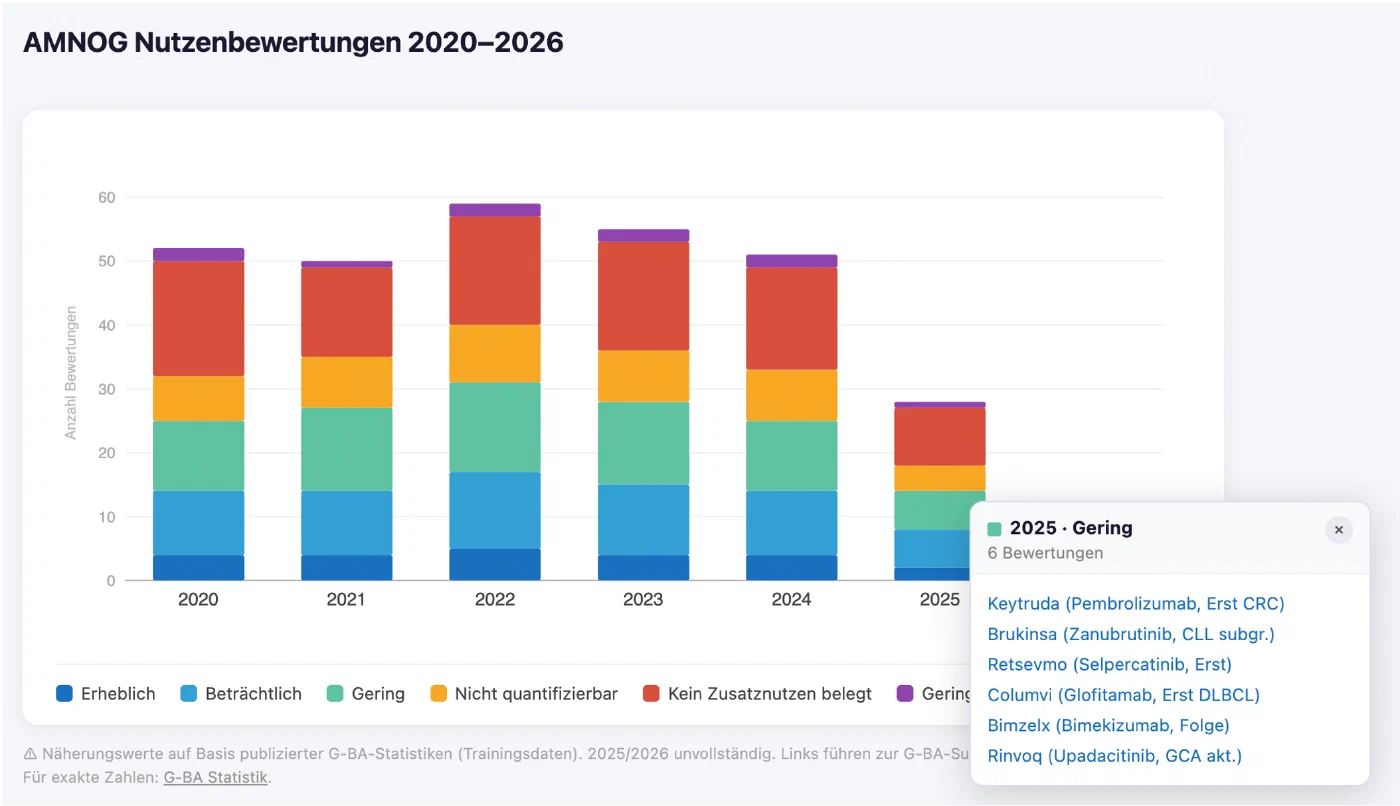
Compare this with the result where the model can use our skill: This time, we know that we can trust the underlying data because we provided it ourselves. Verification and digging deeper is easy because the links go straight to the relevant G-BA decision pages. Same model, same prompt, diverging results. The difference is the data Claude is reasoning from.
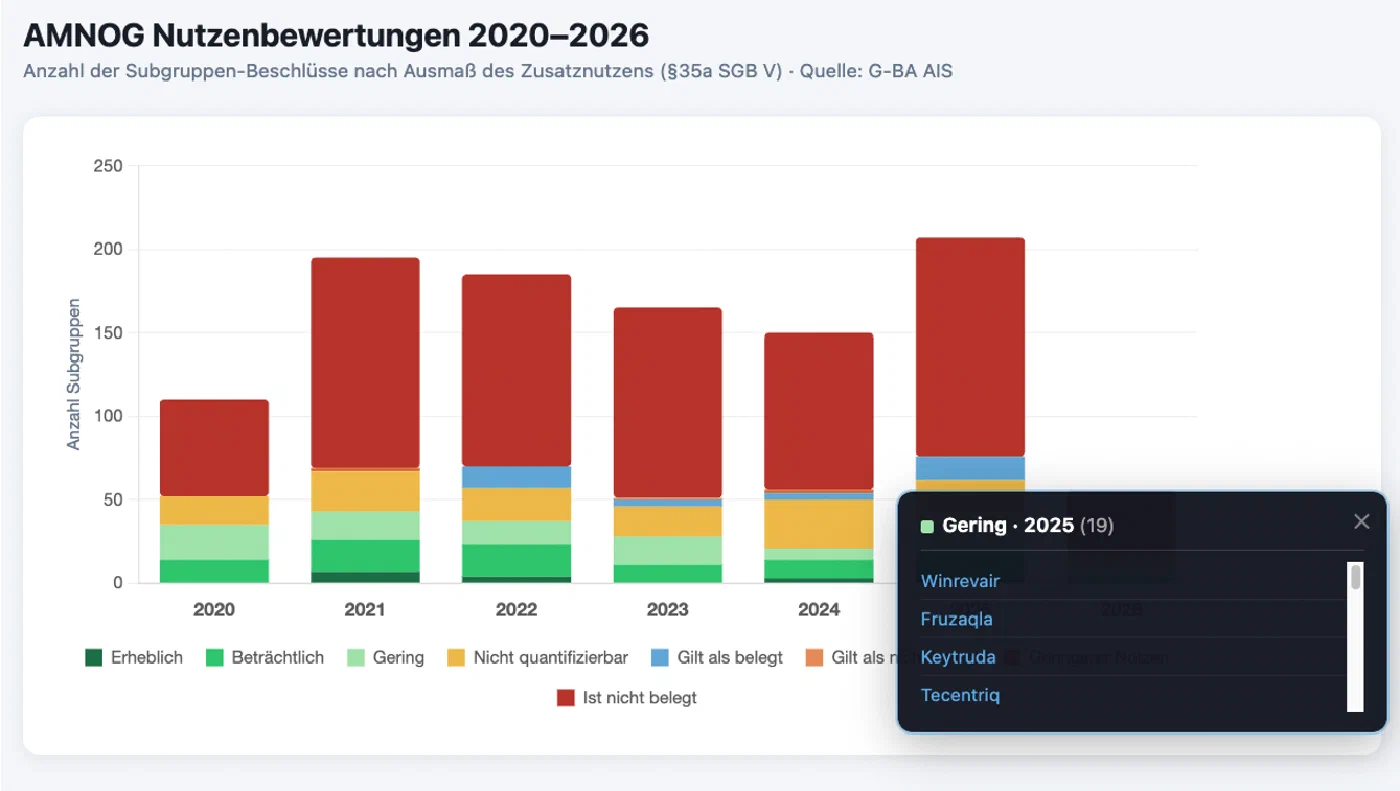
In reality, the queries that a market access team would ask are even more complex than this example. They would ask things like:
- What zVT has the G-BA chosen for other drugs in this indication?
- How are subgroups typically defined in lymphoma assessments?
- Which drugs have time-limited approvals approaching re-evaluation?
- How has the benefit rating for this drug changed across successive re-evaluations?
As we’ve seen before, general-purpose AI cannot answer any of these reliably. The training data has a cutoff; the G-BA publishes new decisions every two weeks. Beyond recency, the model conflates what it has seen in training with what it infers from adjacent cases. It may know a decision in general terms but not know whether it has been superseded, or whether the subgroup definition changed in a follow-up evaluation. A wrong zVT or a missed re-evaluation is not a minor annotation error; it can reframe a pricing strategy or invalidate a competitive benchmark.
What a skill does
A skill packages detailed instructions (pre-written prompts) and custom code (Python or bash) behind a single slash command. The instructions are the briefing which also triggers the skill: how to respond to a category of question, what output format to use, what caveats to apply, when to run which piece of code. The code fetches data from your trusted source, parses it, and injects the result into the session.
A plain language model answers your prompts from patterns learned during training: vague, potentially outdated, with unreliable citations. But if you feed it with trusted and up-to-date data first, the model no longer draws on training memory.
Skills are still limited compared to a full application: no persistent database, no semantic search over large text corpora, no audit log, and code runs locally. For well-scoped tasks tied to structured, publicly available data sources, they deliver substantial capability for modest effort. All major vendors have a comparable concept: Microsoft has Copilot Extensions, Google has Gems.
Skills sit in the middle of a natural progression: shared prompts, then skills with custom code and controlled data sources, then full applications with proper infrastructure. Each step delivers more reliability and capability.
How the AMNOG skill works
The AMNOG skill is possible thanks to the G-BA, who provides a reliable structured XML data feed, updated twice a month. The data feed is available via a personalized URL that needs to be requested via email.
It contains benefit ratings (Zusatznutzen), zVT assignments, indication scope, subgroup definitions, time-limited approvals and the full history of re-evaluations. The format follows an official XML Schema: complete, unambiguous and machine-parseable. This is our trusted source.
The skill enables Claude to access the complete feed reliably and inject the relevant chunks into its memory (saving tokens through pre-filtering). When a user types /amnog followed by a question, the code fetches the complete and most recent XML from the G-BA website, parses and filters it, and then passes the relevant subset to Claude. The code handles data retrieval; the model summarizes and interprets it.
The skill is built around four types of questions. For each type, it contains instructions on how to interpret the G-BA data and how to structure the answer.
Lookup questions ask for a specific recorded fact: which zVT was assigned to drug X, what was the benefit rating for a given subgroup. The answer cites the decision date, the relevant subgroup and the exact official language.
Comparison questions ask how multiple decisions relate: zVT choices across drugs in the same indication, how two benefit ratings differ. Output: a side-by-side table with source references.
Pattern questions ask what the G-BA has tended to do in a therapeutic area: which zVTs appear repeatedly, how subgroup granularity has evolved over time. The answer quantifies the pattern and flags exceptions rather than smoothing them over.
Screening questions ask the skill to surface drugs matching a condition: all drugs with time-limited approvals, all drugs where a re-evaluation is pending within twelve months. Output: a structured list with key fields from the feed.
Try the AMNOG skill
Follow these simple steps to try the skill yourself:
1. Install the skill
To use the AMNOG Skill, you’ll need the Claude desktop app with Cowork mode enabled. After completing the following steps, the /amnog command will be available in all your Claude Cowork session.
- Download this file: amnog.zip
- In the Claude desktop app, go to: Cowork → Customize → Skills → + → Create skill → Upload a skill
- Select the downloaded zip file
2. Register for the G-BA feed
The skill pulls from the G-BA’s Arzneimittel-Informationssystem (AIS). To access it, you need a personal download URL which the G-BA issues by email. Until you provide the URL, the skill will stick to asking for the URL rather than attempt a query.
- Click here to register. You will receive an email with your personal URL within a few minutes.
- Once you have the URL, run
/amnog config set-url <your-url>. - Run
/amnog config showto verify it is saved correctly.
3. Run the self-test
Run /amnog test to verify that the skill is ready. If anything fails, the script will name the likely cause. This will be faster than debugging a real query.
Where skills end
The AMNOG skill relies on the G-BA feed which is clean, structured, and public. That combination is the exception, not the rule. Extending the skill to cover French HAS decisions and UK NICE appraisals alongside AMNOG is possible in principle; in practice, the data formats and decision structures differ enough to require a proper application with a database and query layer.
More fundamentally: a team’s real competitive knowledge sits outside public feeds. Past negotiation outcomes that were never published. Internal analyses of which zVT arguments worked in which markets. The accumulated judgment of experienced pricing and medical affairs staff, all data a skill cannot access. This is where building a proper application makes sense, not because it handles public data better, but because it can be connected to yours.
The interface constraint is real too. Chat works for question and answer. For workflows that need comparison views, structured input formats or persistent context across sessions, it becomes a workaround. And workarounds get clunky quickly.
There is also an efficiency argument. For simple look-ups, like “What is the zVT for Diflusanil?”, a proper search interface would not only be much faster than waiting for Claude to finish his reasoning. It would also be cheaper on the token-side. The skill earns its latency on pattern and screening queries, where the AI does some real work on top of the data.
None of this argues against starting with a skill. Starting with a skill is fast, low-commitment, and produces real working tools. But the path forward is clear: skills are a starting point, not a destination.
