
Data management for early-stage biotechs: how to get started on the right path

Data management at a biotech needs to work for everyone – from CEO’s courting investors to lab scientists designing the next experiment. Get it wrong and you’ll either need to put up with your system’s foibles or go through a painful migration to a new system. Here’s how to get it right from the start
What drives the genesis of biotech startups? In almost all cases, it’s a unique approach to a specific scientific question, or the pioneering use of a novel technology. The precious data the biotech accumulates in exploration of this idea is what defines its chances of success. It won’t discover novel drugs without that data.
To begin with, generating that data is all about exploring the original hypothesis. But very quickly, how that data is stored, processed, integrated, visualised and interpreted begins to define the nature of the experimentation.
The data also needs to work for CEOs and CSOs, as it will often inform what should be presented in pitches to investors, or which clinical program should be focused upon. For all these reasons, data management is a key question for every biotech to confront early on.
In fact, many biotech founders see fast, convenient access to quality-controlled data as the single most important factor to enable good decision making.
Four strategies for data management in early stage biotechs
At the initial ideas stage, it’s pretty normal – and workable – for data to be stored on local hard drives and emailed as Excel attachments. But demands quickly outgrow that setup once a biotech begins producing data in the early discovery stage, as more people come on board and the volume and complexity of data increases.
There are four main approaches to building a data infrastructure in biotechs.
Strategy I: Adopt well-established data management software
On the upside, people coming from pharma will likely be familiar with software such as Dotmatics or IDBS Activity Base for screening data. That means they may find these systems easy to use, despite their dated frontends. Downsides include the high upfront cost and a rather closed architecture that is, in practice, more difficult to customise than promised.

Strategy II: Choose a modern end-to-end biotech R&D SaaS solution
Over the past few years, several new entrants, such as Benchling, LabGuru and LabLynx have emerged. These systems are far more user friendly than the well-established software packages listed above and tend to be more open in terms of data structures and APIs. But not all scientists will appreciate the way they subtly nudge you towards moving entire workflows onto their platforms. In addition, like their more established competitors, none work out of the box; customisation is not just a feature, but a necessary step.
Strategy III: Build an entire system from scratch
High cost precludes this from being an option for the vast majority of biotechs. But it may be the right strategy for those with highly demanding data volume or computing power requirements, such as image data analysis or mass spectrometry. This is still a niche, but a growing one, as software technology becomes an ever more important part of biotech’s R&D platform.
However, all of these strategies have one downside in common: they set you on a path that’s very difficult to change. Data accumulates, teams learn to live with certain software and the idea of migrating data to a new system begins to look pejoratively painful. Often, biotechs will stick with a system even if it’s slowing them down.
“It took us six months getting into [software], and once we were in, we had to build a team of 5+ FTEs just to customise,” says one Cambridge (MA) biotech CEO. “What some established data management tool sold us as highly customizable turned out to be basically having to build the whole system from scratch in the suppliers framework.”
But there comes a time to cut your losses, he says: “Now, we are moving the core data processing parts to a standard cloud provider; that’s what we should have done [in the first place].”
“Now, we are moving the core data processing parts to a standard cloud provider; that’s what we should have done [in the first place].”
Strategy IV: Start with a custom data management system built from commodity cloud components.
With the advent of managed services in the cloud, most of the basic components you need to piece together a data management system have become user-friendly SaaS cloud software. This commoditisation and consumerisation trend of computing and storage has given rise to a fourth strategy for early stage biotechs.
The advantages of starting with something that’s custom built, but from existing cloud components, are many. For a start, there’s no need to press your ideas into your supplier's framework (unlike in Strategies I and II), which saves money and time. It’s also cheaper than building a bespoke system from scratch and more flexible from the very beginning. Perhaps most importantly, it’s faster – so your ideas and research are not slowed down by the vendor’s framework. At the earliest stages of setting up a biotech, this is absolutely vital.
Moreover, an open cloud-based system is an excellent starting point for building machine learning and artificial intelligence tools into the R&D platform. More and more biotechs are realising that AI is more than a buzzword to woo investors, and has the potential to catalyse, streamline and augment their research.
Although you don’t get the slick UX experience you might get from a more integrated solution, everything will be seamlessly connected and synced to everything else. But at a time when you’re still understanding where your research is going and the data it needs, such systems can be restrictive.
With a custom data management system built from commodity cloud components, you’re also not committing to a specifc software vendor, you can also retain strategic flexibility. Should the time come to move to a more integrated solution, data migration is relatively simple and obstacle-free. With a bit of planning ahead, the migration path can be further smoothed by setting up data schemas in a way that makes the transformation into a vendor’s schema less cumbersome.
A simple example: an assay data ingestion pipeline in commodity cloud components
One of the first data pipelines many early-stage biotechs need to build is the early-stage assay data analysis pipeline. Let’s look at how this could be built from commodity components in the Google Cloud.
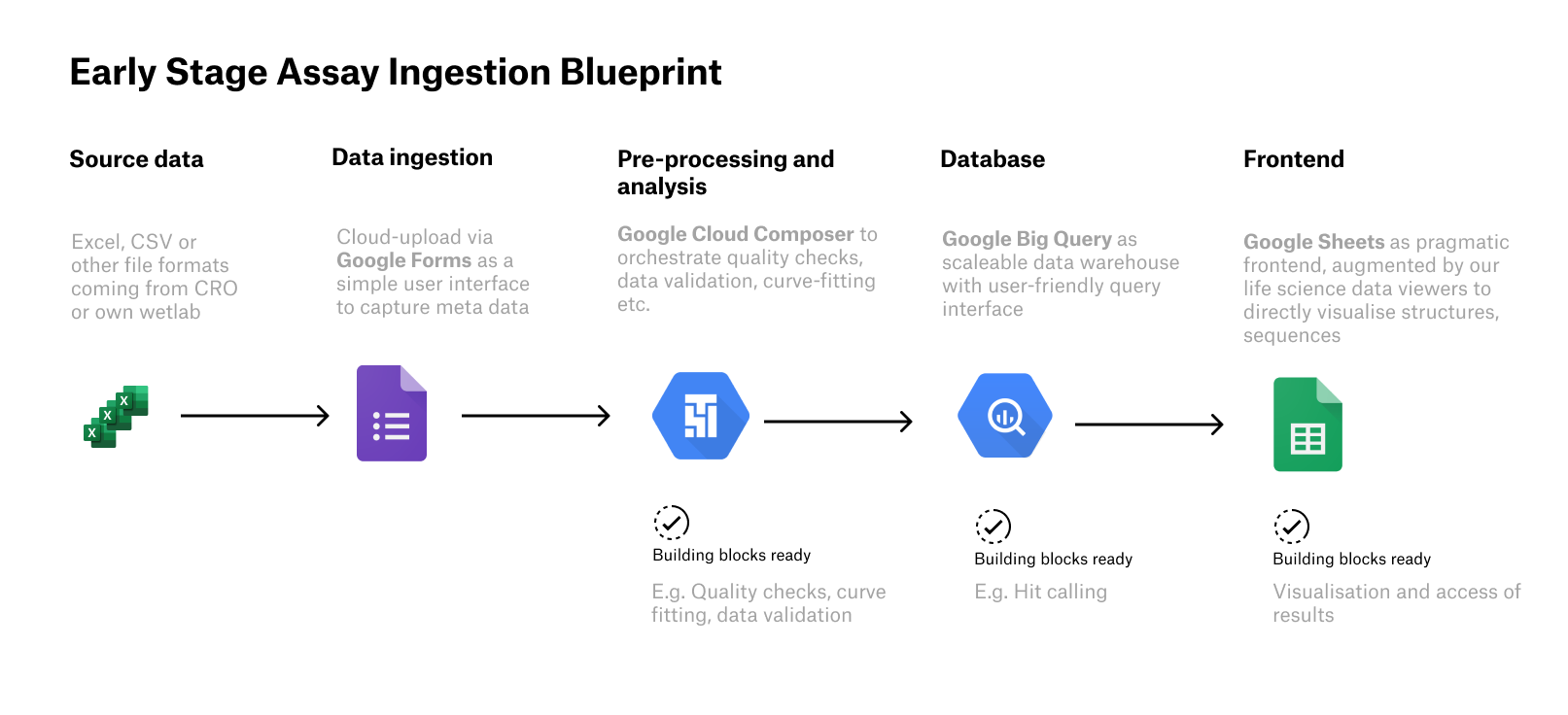
At some point you might probably work with a CRO to perform different types of standard assays for you. Based on your SOPs, the CRO’s team defines how to get the data back to you. Given that few industry-wide standards exist, this is still likely to be an Excel or CSV file.
This is where Google Forms comes in super handy. You simply create a form that enables metadata to be inputted and CSV and Excel files to be uploaded. This is already better than using email attachments, since all files are stored in a structured manner in Google Sheets and Google Drive. And scientists can set up different Google Forms to suit their needs.
An orchestration platform (such as Google Cloud Composer) works well for pre-processing, quality checks, and analytical steps that can be automated, because the ingestion into your analytics database is reproducible – so you won’t end up with a data silo. Building on top of services as Google Cloud Composer (managed Airflow service) also enables you to easily extend your data preprocessing if needed.
Modern fully managed analytics databases can now easily deal with large volumes of data, so there’s no need for system administrators tweaking parameters to get queries running faster. With convenient and intuitive interfaces on databases such as Big Query, data is easily accessible as well – there’s no need to be fluent in SQL. For scientists tired of learning new interfaces time and time again, the benefits are clear. They can just drag and drop IC50 curves directly into Google sheets – which is integrated with Big Query – without needing a single line of code.
Setting up such a system in a future-proof and user-centric way requires comprehensive understanding of a biotech's needs – both now, and 3-5 years down the line – combined with solid engineering skills. Experienced tech-savvy computational biologists or chemists could provide that, as could a specialised partner. We’re happy to point you in the right direction, or support the full build out. Just get in touch.
Further reading
Modern biotech data infrastructure (Brian Naughton’s blog) explains how to get started from scratch and discusses the different needs of tech biotech startups.